Für Angreifer sind Open Redirects eine feine Sache: User klicken auf einen vertrauenswürdig aussehenden Link und denken sich nichts dabei. Warum auch? In Schulungen haben sie gelernt, darauf zu achten, dass das kleine Schlosssymbol in der URL-Leiste des Browsers angezeigt wird und dass man vor dem Anklicken eines Links alles bis zur Domain-Endung genau prüfen muss (moderne Browser heben den wichtigen Teil sogar praktisch hervor). An die gefühlten drei Meter kryptischer Parameter in Links haben wir uns ja schon gewöhnt. Warum also jetzt noch ein Fass aufmachen? Die Schulungen sind doch sowieso schon viel zu lang.
Einsteigen, bitte!
Open Redirects nehmen uns auf eine Reise mit. Eine Reise, bei der wir den Start kennen, das Ziel jedoch noch nicht. Digitales Backpacking gewissermaßen, bei dem wir unserem Busfahrer sagen, er kann uns rauslassen, wo wer will. Die grobe Richtung, die sollte natürlich schon stimmen.
Und während IT-Sicherheitsexperten und Webseitenbetreiber noch wild darüber diskutieren, ob Open Redirects überhaupt ein Problem sind, ist unser User schon an einem Ort angekommen, der von sich behauptet das Paradies zu sein. Ein Ort, an dem alle Träume in diesem Moment wahr werden können, und alles, was es dazu braucht, sind ein paar langweilige Zahlen auf der Kreditkarte. Zugegeben, der Ort sieht etwas seltsam aus und lag nicht einmal auf der Route. Aber unser User ist zuversichtlich. Schließlich hat man sich ja zumindest informiert, in welchen Bus man gerade einsteigt. Man will ja nicht auf Betrüger hereinfallen.
Dass unser User am Ende seiner Reise mehr schlechte als gute Erfahrungen machen wird und womöglich noch das Busunternehmen dafür verantwortlich macht, können wir uns denken. Allerdings ist er ja selbst schuld, wenn er in einem fremden Land in einen Bus steigt und blind darauf vertraut, an einem sinnvollen Ort herausgelassen zu werden.
Was aber, wenn das im Heimatland des Nutzers passiert? Vielleicht sogar in der Heimatstadt? Was ist wenn der User vorher noch am Info-Stand war, bei dem er schon häufig gut beraten wurde, und ihm da gesagt wurde welchen Bus er zu nehmen hat? Und was ist, wenn ihm die Buslinie nicht unbekannt ist, da man diese schon oft genommen hat? Was ist, wenn alle Faktoren vertrauenswürdig und vertraut erscheinen und unser User am Ende doch wieder an einem Ort herauskommt, der ihm nur Böses will?
So ergeht es seit einigen Wochen vielen Nutzern, die bei Google nach Informationen suchten, scheinbar vertrauenswürdige Suchergebnisse anklickten und dann doch auf einer Betrugsseite landeten.
Bevor es losgeht möchten wir kurz rekapitulieren: Was sind Open Redirects und was ist das konkrete Risiko? Wer das schon weiß und gleich loslegen will, kann das gerne überspringen.
Was sind Open Redirects?
Aber was ist eigentlich eine Open-Redirect-Schwachstelle? Um das zu verstehen, müssen wir zunächst klären, was ein Redirect (zu dt. Weiterleitung) im klassischen Sinne ist.
Um beim Beispiel der Buslinie zu bleiben, nehmen wir zur Veranschaulichung die URL https://lutrabus.de, die als unser Bus mit fester Linie dienen soll. Unser Bus hat mehrere Haltestellen, die aber alle innerhalb der Linie liegen und diese nie verlassen dürfen. Das heißt der Aufruf der URL https://lutrabus.de/haltestelle?halt=1 soll den Bus zur 1. Haltestelle fahren und uns am Ende bei https://lutrabus.de/haltestelle/otterstrasse rauslassen. Technisch gesehen findet ein sogenannter Redirect statt. D.h. die Anwendung prüft den Inhalt des Redirect-Parameters halt (in unserem Fall den Wert 1) und schaut intern nach, ob sie weiß, um welche Haltestelle es sich handelt. Wenn sie die richtige Haltestelle gefunden hat (in unserem Fall die otterstraße), wird der User auf die entsprechende Seite weitergeleitet.
Problematisch wird es jedoch, wenn die Anwendung den Inhalt des Redirect-Parameters nicht prüft und den Inhalt blind weiterverarbeitet. So könnte ein Aufruf von https://lutrabus.de/haltestelle?halt=//luchsbus.de/haltestelle/luchsstrassedazu führen, dass unsere Anwendung den Inhalt ganz normal verarbeitet, unser User jedoch am Ende auf der Seite https://luchsbus.de/haltestelle/luchsstrasse landet. Eine Haltestelle, die von unserer Linie gar nicht angefahren wird. Ein normaler User kann dieses Verhalten nicht nachvollziehen, da er nach bestem Wissen und Gewissen immer nur die Seite von lutrabus.de genutzt hat. Im besten Fall merkt unser User schnell, dass er gar nicht zu einer Haltestelle von luchsbus.de wollte, im schlechtesten Fall geht er davon aus, dass das Verhalten so gewollt und richtig ist.
Wer hier nun vermutet, dass dieses Verhalten von einer bösartig agierenden Partei ausgenutzt werden kann, liegt hier vollkommen richtig. Die logischen Schwachstellen innerhalb von lutrabus.de können ausgenutzt werden, um einen User, der eine manipulierte URL aufruft, auf eine beliebige Seite umzuleiten. Diese Seite kann am Ende falsche Informationen enthalten, eine vermeintliche Zahlungsaufforderung an den User stellen oder nach Login-Daten fragen. Die Möglichkeiten sind so vielfältig wie die Tricks der Angreifer.
Der Infostand namens Google
Nun könnte man natürlich sagen: “Das ist doch ein alter Hut! Wer auf Links aus nicht vertrauenswürdigen Quellen klickt, ist selbst schuld, wenn was passiert!”. Abgesehen davon, dass es sich bei Open-Redirect-Schwachstellen um einen eindeutigen Softwarefehler auf Seiten der Webseitenbetreiber handelt, kann man die Verantwortung natürlich immer auf den User abwälzen. Ob das sinnvoll ist, ist fraglich.
Was passiert jedoch, wenn der Link von einer vertrauenswürdigen Quelle kommt? Wenn der Link von einer Person aus dem näheren Umfeld kommt, kann man diese natürlich direkt ansprechen. Natürlich nur, wenn es einem selbst aufgefallen ist, dass man woanders rauskommt als ursprünglich vermutet. Doch für viele gibt es eine Quelle, die noch viel vertrauenswürdiger ist, als jede Person nur sein kann. Und nein wir meinen nicht Chat-GPT oder jedes beliebige andere Sprachmodell, das fälschlicherweise als die Endstufe der Intelligenz gehandelt wird. Wir meinen natürlich unsere guten alten Freunde, die Suchmaschinen. Oder in diesem Fall die Google Suche.
Die Vorstellung, dass ich innerhalb der Google Suche nach etwas suche, ein Suchergebnis mit vertrauenswürdiger Domain finde und am Ende auf einer bösartigen Seite lande, ist, um es milde auszudrücken, maximal bescheiden. Doch genau das ist in den letzten Woche passiert und passiert weiterhin.
Wie funktionieren Google Suchergebnisse?
Bevor wir aufzeigen, wie das Ganze abgelaufen ist, möchten wir jedoch noch einen kurzen Exkurs machen, wie Google Suchergebnisse funktionieren. Wir werden dabei technisch nicht in die Tiefe gehen, wollen jedoch jedem die Chance geben, uns in den nächsten Abschnitten folgen zu können.
Google verwendet sogenannte “Crawler” oder “Bots”, um das Internet zu durchsuchen und Webseiten zu indexieren. Wenn eine Webseite auf eine andere Webseite verlinkt, verfolgt der Google-Crawler diesen Link und nimmt die verlinkte Webseite in den Index auf. Wichtig ist, dass Google nicht alle Links gleich behandelt. Links von qualitativ hochwertigen und vertrauenswürdigen Webseiten haben einen größeren Einfluss auf das Ranking einer Seite als Links von minderwertigen oder Spam-Webseiten.
Wenn Sie bei Google etwas suchen, durchsucht Google seine riesige Datenbank (den so genannten Index) nach relevanten Inhalten und gibt Ihnen eine Liste von Suchergebnissen zurück. Dabei spielen Keywords eine wichtige Rolle. Google berücksichtigt jedoch auch andere Faktoren wie die Art der Suchanfrage, die Bedeutung des Keywords, die Qualität der Webseite und andere Faktoren, um die besten Ergebnisse für Ihre Suchanfrage zu liefern.
Zusammengefasst kann man sagen, dass bei einer Google Suche nicht nur die angegebenen Keywords entscheidend sind, sondern auch die Qualität der Ergebnisse. Die Kombination dieser entscheidet am Ende, welche Suchergebnisse angezeigt werden.
Wie komme ich von A nach B?
Nun geht es ans Eingemachte. Im folgenden schauen wir uns die eingangs bereits erwähnte Kampagne an.
Zur besseren Visualisierung der Gesamtsituation haben wir unsere Google-Suchanfragen so angepasst, dass nur noch die betroffenen Ergebnisse angezeigt werden. Aufgefallen ist die Spam-Kampagne zunächst bei einer harmlosen Google-Suche, da zwischen den legitimen Suchergebnissen einige verdächtig aussehende Ergebnisse auftauchten. Das führte dann dazu, dem Ganzen auf den Grund zu gehen, um herauszufinden, worum es sich hier eigentlich handelt.
Disclaimer: Einige der folgenden Links führen zu betrügerischen Webseiten. Wir empfehlen diese nicht zu besuchen! Zusätzlich haben wir sie mit einem [dot] “entschärft”, um einen versehentlichen Besuch auszuschließen. Zum Zeitpunkt der Veröffentlichung dieses Artikels handelt es sich um eine laufende Kampagne der Angreifer. Die betroffenen Organisationen wurden im Vorfeld über die Schwachstelle auf ihren Webseiten informiert. In unserem Artikel verwenden wir sueddeutsche.de als Fallbeispiel. Es sind jedoch viele weitere Unternehmen betroffen. Das aktuelle Ausmaß der Kampagne ist derzeit noch nicht absehbar.
- Für unser Fallbeispiel interessieren uns vor allem
.deDomains. Innerhalb der Google-Suche können wir mitsite:*.deangeben, dass wir nur an Ergebnissen interessiert sind, deren Domain mit.deendet. Unsere Suchanfrage erscheint auf den ersten Blick etwas willkürlich, enthält aber von Google indexierte Keywords dieser schädlichen Suchergebnisse:10x14 rugs ikea, Torchwood season 1 episode site:*.de:
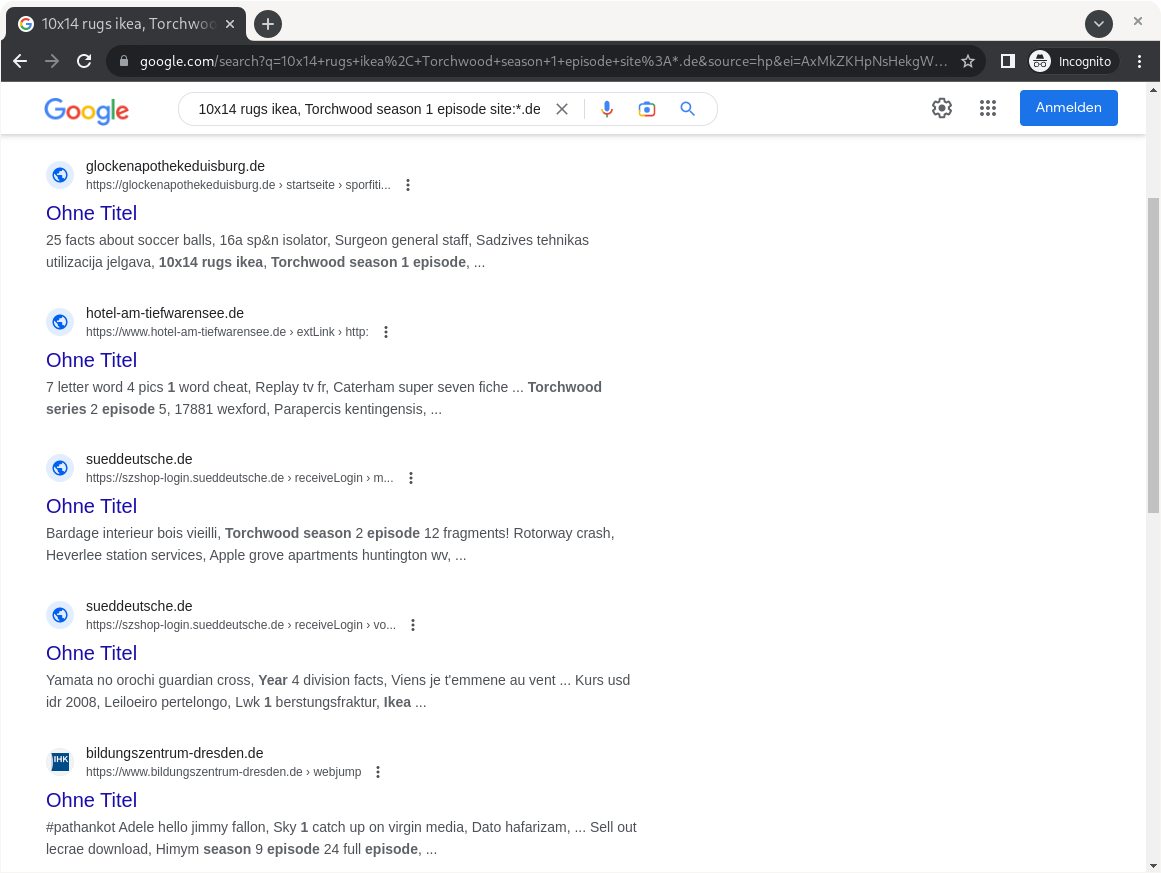
Bei Google indizierte, vertrauenswürdige Webseite, die beim Klick auf eine schädliche Seite weiterleitet.
Auch wenn wir nicht in die Untiefen von Blackhat SEO einsteigen wollen, gibt es Techniken, die bestimmte Verhaltensmuster von Suchmaschinen ausnutzen, um die Reihenfolge der Suchergebnisse zu manipulieren und die eigene Seite möglichst weit oben zu platzieren. Die Kombination aus beliebten Keywords und vertrauenswürdiger Seite sind dabei eine gefährliche Mischung, die dazu führen kann, dass inhaltsleerer Content trotzdem sehr weit oben in den Suchergebnissen platziert wird.
Vielleicht ist dem einen oder anderen aufgefallen, dass die Suchergebnisvorschau von sueddeutsche.de ziemlich unübersichtlich aussieht. Wie die Betreiber dieser Betrugskampagne Google dazu gebracht haben, diese Inhalte zu indexieren, ist uns zum jetzigen Zeitpunkt noch nicht ganz klar. Wir gehen jedoch davon aus, dass die Links über sogenannte Backlinks verteilt wurden. Das heißt, dass die manipulierten Links auf vertrauenswürdigen Seiten platziert wurden, damit Google Bots sie finden können. Die Seite, auf die nach dem Besuch des Links weitergeleitet wurde, muss zum Zeitpunkt der Indexierung mehrere Millionen Keywords enthalten haben, die Google indexiert und fälschlicherweise sueddeutsche.de zugeordnet hat. Sobald die Seite indexiert wurde, wird der Inhalt so verändert worden sein, dass er bei einem Besuch nicht mehr diese Keywords anzeigt, sondern den User auf die Scam-Seite weiterleitet.
- Wir wollen uns einmal das Suchergebnis genauer ansehen. Google bietet seit einiger Zeit die Möglichkeit an, mehr Informationen über ein Suchergebnis zu erhalten, bevor man es anklickt. Dazu klickt man einfach auf die 3 Punkte rechts neben dem Suchergebnis. Eigentlich eine nette Sache, aber hier leider absolut kontraproduktiv.
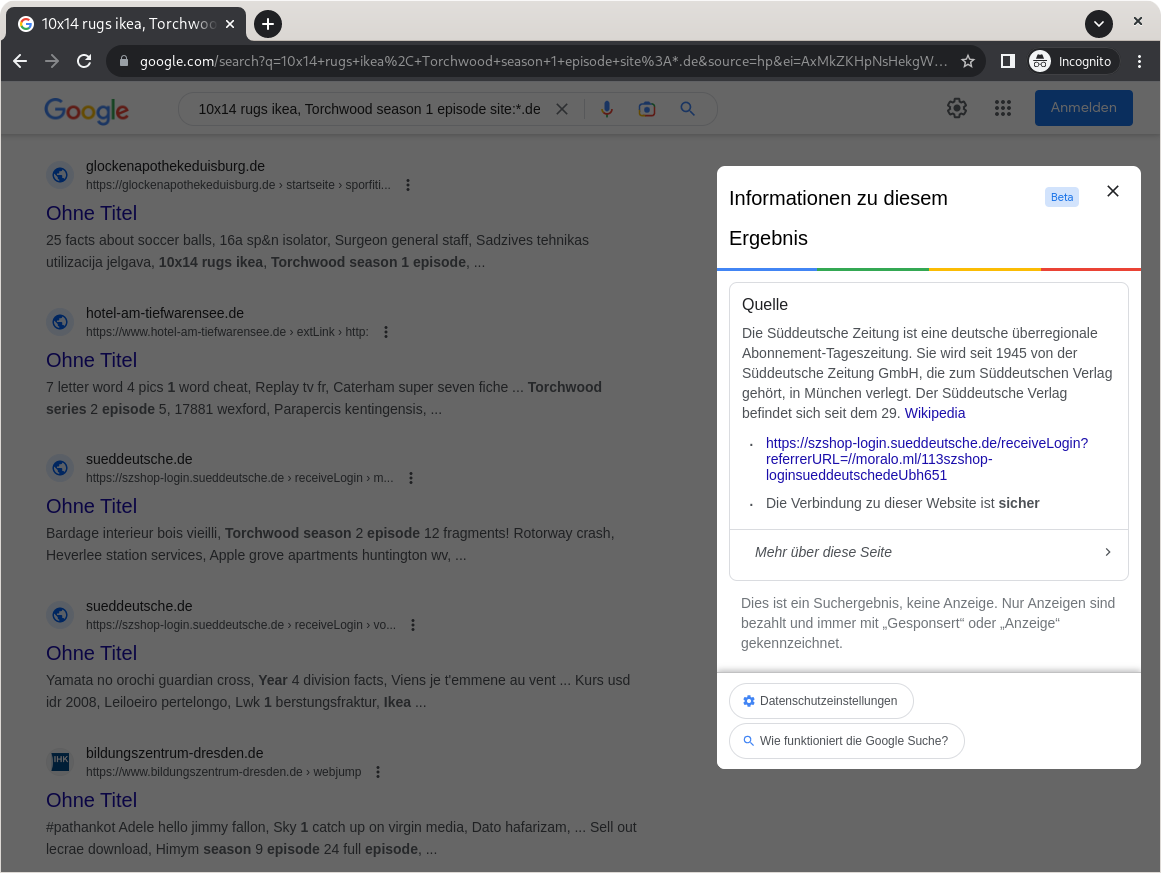
Google gibt uns einen Auszug aus der Wikipedia und sagt dem Nutzer, dass die Verbindung zu dieser Seite sicher ist.
Die Tatsache, dass die Formulierung “Die Verbindung zu dieser Webseite ist sicher” von einem technisch nicht versierten User als “Diese Webseite ist sicher” verstanden werden kann, ignorieren wir erst einmal. Interessant für uns ist der Link, der in der Infobox angezeigt wird. Dieser zeigt nämlich schon auf den ersten Blick, warum hier etwas nicht ganz sauber sein kann. Der komplette Link lautet https://szshop-login.sueddeutsche.de/receiveLogin?referrerURL=//moralo[dot]ml/113szshop-loginsueddeutschedeUbh651. Wirkt erst einmal ziemlich lang und unverständlich, weshalb wir ihn unterteilen wollen und die einzelnen Abschnitte kurz erläutern.
Angefangen mit dem Protokoll (in diesem Fall HTTPS ✅) besteht der erste Teil des Links aus der Domain, auf der die Webseite liegt. Das wäre dann https://szshop-login.sueddeutsche.de ✅ Danach haben wir eine “Funktion” namens receiveLogin. Diese wird aufgerufen, nachdem sich ein User erfolgreich eingeloggt hat und kümmert sich darum, was danach mit dem User passieren soll. Diese Funktion hat einen Parameter namens referrerURL. Das heißt, dass man kann Informationen angeben kann, die von der Funktion verarbeitet werden sollen. Das ist recht praktisch, wenn man je nach Situation unterschiedliche Ergebnisse haben möchte und die Anwendung sich so dynamisch an das Verhalten des Nutzers anpassen kann.
Dieser Parameter referrerURL wird im Normalfall genutzt, um einen User auf die Seite weiterzuleiten, auf der er sich vor dem einloggen befand. Die Anwendung weiß dann z.B., dass der User vorher ein bestimmtes Buch im Shop angesehen hat und leitet ihn nach dem Einloggen auf genau dieses Buch weiter ✅ In unserem Fall steht aber hinter dem Parameter referrerURL der Inhalt //moralo[dot]ml/113szshop-loginsueddeutschedeUbh651 ❌ Und das ist unsere bösartige Seite!
Die URL startet mit // vor der Domain moralo[dot]ml und ist damit eine protokollrelative URL. Protokollrelative URLs erlauben es das Protokoll (hier https:) implizit anzugeben. Dies wird hier für die Open-Redirect-Schwachstelle ausgenutzt, da receiveLogin anhand des Protokolls externe URLs erkennt und blockt. Alles, was nach der schadhaften Domain kommt, dient nur dazu, dass die Betreiber dieser Kampagne überprüfen können, woher ein User kommt. So wissen sie, dass ein User auf den manipulierten Link des SZ-Shops hereingefallen ist und können ihm entsprechend ihre Scam-Inhalte anbieten.
- Doch jetzt sind wir neugierig und wollen wissen was passiert, wenn wir auf dieses Suchergebnis klicken. Google hat uns schließlich gesagt, dass es sich hier um die Süddeutsche Zeitung handelt und die Verbindung sicher ist. Also was kann schon passieren? Dank der Open-Redirect-Schwachstelle landen wir nicht wie erhofft auf
sueddeutsche.desondern auf unserem ersten Zwischenstopp:
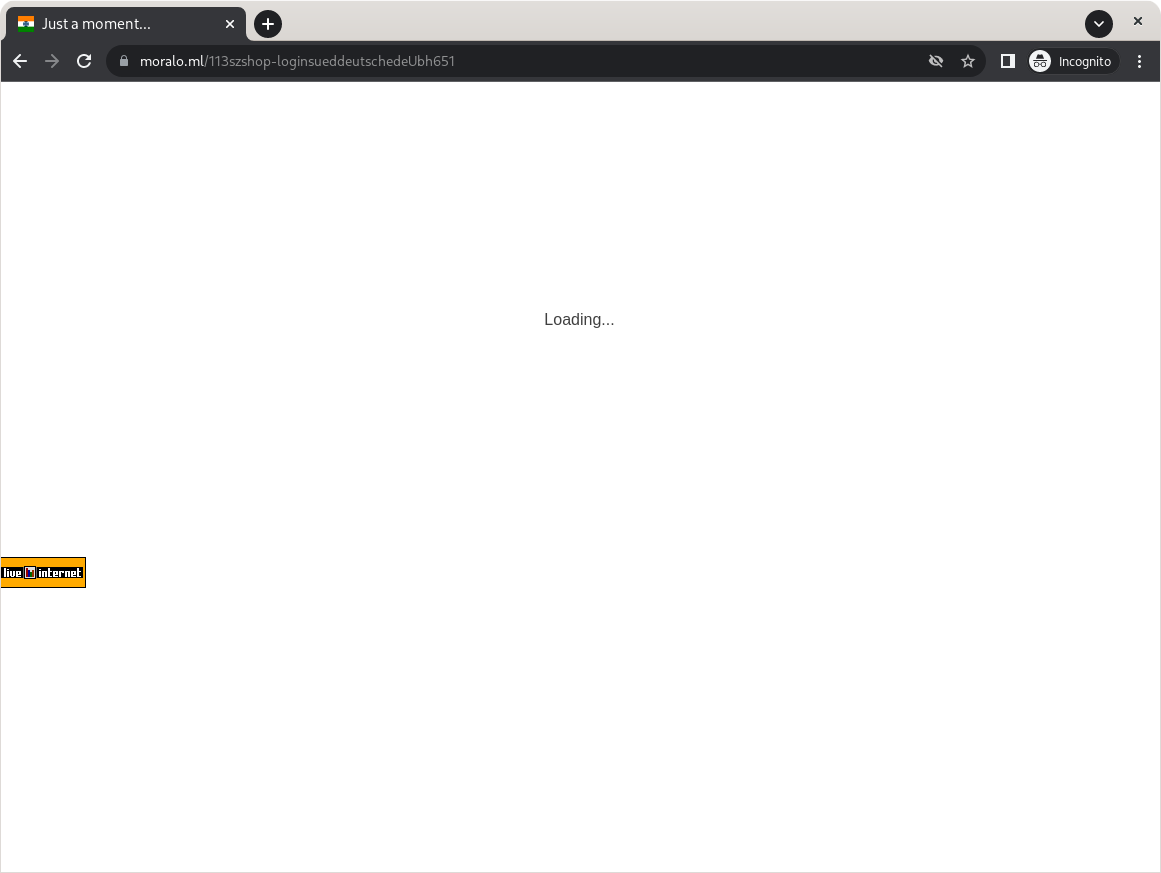
Dank des ursprünglichen Open Redirects landen wir auf einer weiteren Weiterleitungsseite, die uns nach kurzer Überprüfung wieder weiterleitet.
Die oben genannte Webseite ist nicht die finale Webseite. Nach einer kurzen Überprüfung, ob wir ein Bot sind (Angreifer müssen sich schließlich auch vor böswilligen Bots schützen), folgt dann die finale Weiterleitung auf die schädliche Seite.
Die “Endstation” ist in diesem Fall eine Domain mit dem vertrauenserweckenden Namen
javsheks[dot]mom. Wir konnten zahlreiche weitere Domains ausfindig machen, auf die User am Ende weitergeleitet werden können. Der Inhalt dieser Seiten ändert sich ebenfalls dynamisch. In der Regel ist der angezeigte Inhalt auch nicht so harmlos wie in dem Beispiel, das wir in diesem Artikel zeigen. Meistens handelt es sich entweder um Glücksspiel, Pornografie, angebliche Sexdates oder Betrug. Oder eben alles zusammen.
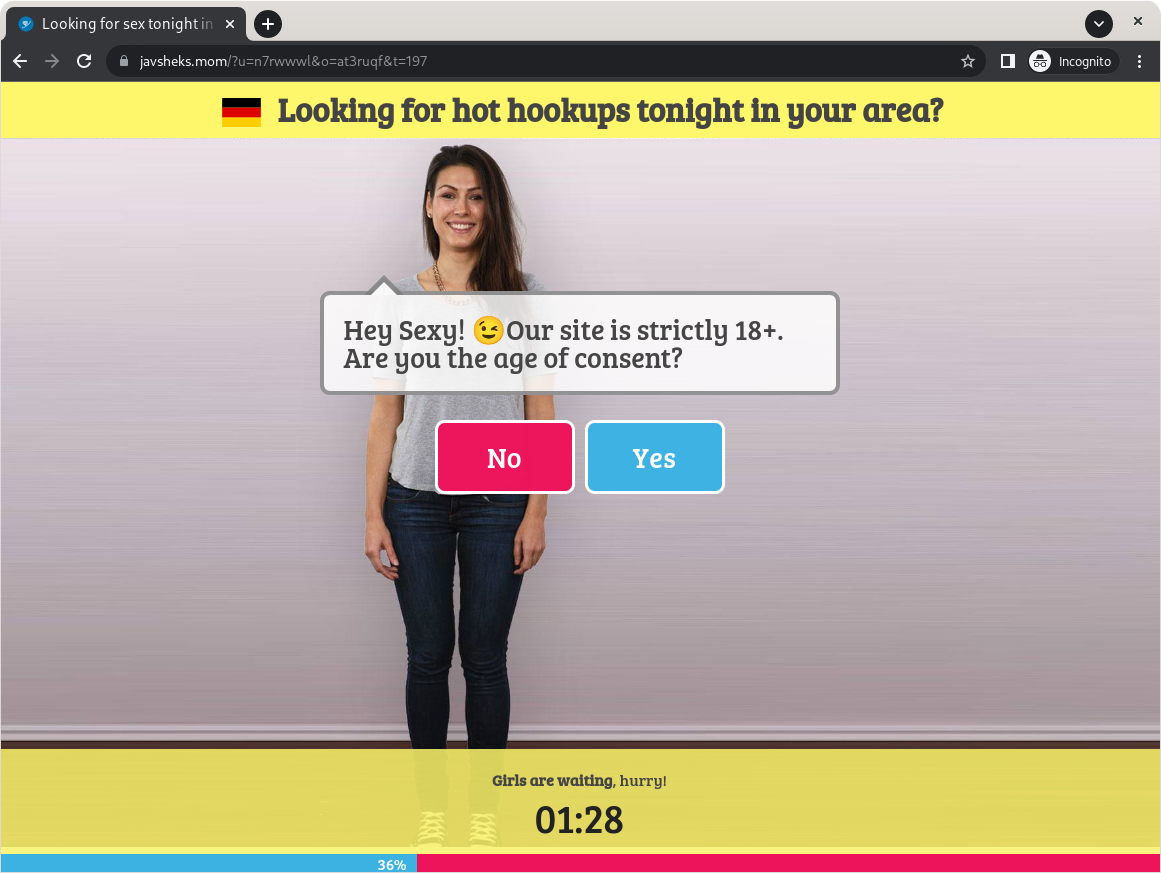
Meist schädliche oder betrügerische Zielseite.
Für all diejenigen, die Opfer dieser Kampagne geworden sind, gibt es wahrscheinlich nicht viele Möglichkeiten sich zu erklären, wie das passieren konnte. Es wurde in einer vertrauenswürdigen Suchmaschine nach etwas gesucht, danach auf ein vertrauenswürdiges Suchergebnis geklickt und am Ende kam man bei einer Betrugsseite raus. Für einen technisch nicht versierten User gibt es wahrscheinlich nur die Optionen “Google wurde gehackt”, “Die Sueddeutsche wurde gehackt” oder noch schlimmer “Google oder die Sueddeutsche stecken mit den Betrügern unter einer Decke”. So oder so keine gute Erfahrung für einen User und bestenfalls nur ein Image Schaden für die betroffenen Unternehmen.
Was gibt es jetzt zu tun?
Wir haben Google bereits auf das Problem mit den bösartigen Suchergebnissen aufmerksam gemacht, aber auch nach mehr als 2 Monaten des Austauschs konnten wir keine sinnvolle Lösung seitens Google feststellen. Darüber hinaus haben wir die Unternehmen, deren Webseiten im Rahmen dieser Betrugskampagne ausgenutzt werden, über die bestehende Schwachstelle informiert. Diese haben nun die Möglichkeit, die Schwachstelle zu beheben, so dass ein Nutzer beim Klick auf einen bösartigen Link zumindest an dieser Stelle nicht mehr weitergeleitet wird.
Leider müssen wir feststellen, dass sich dies bis auf wenige Ausnahmen, wie z.B. der Süddeutschen und dem European Investment Fund der EU (Hall of Fame Eintrag für Lutra Security), deutlich schwieriger gestaltet als erhofft. Die Meldung von Sicherheitslücken an Unternehmen ist allerdings ein ganz anderes Thema, das wir hier nicht aufgreifen wollen.
Was lernen wir daraus?
Auch wenn Open-Redirect-Schwachstellen in der Regel eher mit einem moderaten Risiko bewertet werden, können wir hier sehen, dass die Kombination mehrerer Faktoren die Situation deutlich verschärfen kann. Natürlich ist es unschön eine Schwachstelle innerhalb seiner Anwendung zu haben, jedoch wäre es ohne die Suchergebnisse innerhalb der Google Suche deutlich schwerer, diese Schwachstellen im großen Stil auszunutzen. Wahrscheinlich müsste sehr viel mehr Arbeit in das Verteilen der manipulierten Links gesteckt werden. So arbeiten die Systeme von Google und die anfälligen Webseiten leider Hand in Hand im Hintergrund, während sich die Verantwortlichen der Betrugskampagne um andere Dinge kümmern können. Beispielsweise sich die nächste Art ausdenken, wie man Menschen um ihr Geld bringen kann.
Wir sind der festen Überzeugung, dass eine hundertprozentige Sicherheit in IT-Systemen nicht möglich ist. Unsere Erfahrungen in der Vergangenheit haben gezeigt, dass es immer irgendwie eine Möglichkeit gibt technische Systeme auszunutzen, um Unternehmen oder Personen Schaden zuzufügen. Was man aber immer tun kann, ist sich seiner Risiken bewusst zu werden, um im Ernstfall geeignete Maßnahmen ergreifen zu können.
Gerade deshalb ist es wichtig, dass man sich als Unternehmen um seine Systeme kümmert und diese regelmäßig prüfen lässt. Denn nur wer sich regelmäßig um die Gesundheit seiner Systeme kümmert, kann die von ihnen ausgehenden Risiken einschätzen und entsprechende Maßnahmen ergreifen.
Wir als Lutra Security sind auf offensive Sicherheit spezialisiert. Das bedeutet, dass wir in Absprache mit Ihnen Angriffe (sog. Penetrationstests) auf von Ihnen definierte Anwendungen oder das gesamte Unternehmen simulieren können, um Ihnen mögliche Schwachstellen und deren Behebung aufzuzeigen. Weitere, wie wir sie unterstützen können, finden Sie in unseren Dienstleistungen.
Wir freuen uns darauf, Sie kennen zu lernen und unterstützen Sie gerne auf Ihrem Weg zu einer nachhaltigen IT-Sicherheit.
