Open Redirects are a great thing for attackers: users click on a trustworthy-looking link and think nothing of it. Why should they? They have learned in various repetitive trainings to look for the little lock icon in the URL bar of the browser and to check everything down to the domain extension before clicking on a link (modern browsers even highlight the important part). The boatload of cryptic parameters afterwards won’t bother us any more — we are used to this by now. So why make a fuss about it? The training courses are far too long anyway.
All aboard!
Open Redirects takes us on a journey. A journey where we know the start, but not yet the destination. Digital backpacking so to say, where we tell our bus driver to let us off wherever he wants. Of course, we have given a rough direction!
And while IT security experts and website operators are still debating whether Open Redirects are a problem after all, our user has already arrived at a place that claims to be paradise. A place where all dreams can come true at this very moment, and all it takes is a few boring numbers on a credit card. Admittedly, the place looks a bit strange and wasn’t even on the route. But our user is confident. At least, they had a rough idea which bus they were getting on. You don’t want to fall for a scam after all.
We can imagine that at the end of this journey, our user will have experienced more bad than good and may even blame the bus company. Nevertheless, it is his own fault for getting on a bus in a foreign country and blindly trusting that he will be dropped off at a reasonable location.
But what if this happens in the user’s home country? Maybe even in their home town? What if the user had previously visited the information booth where they regularly gather information and was told which bus to take? And what if they are familiar with the bus route, having travelled it many times before? What if all the factors seem trustworthy and familiar, and yet our user ends up in a place that only wants to harm them?
This has been happening for several weeks to many users who have searched for information on Google, clicked on seemingly trustworthy search results and ended up on a fraudulent website.
Before we get started, let’s have a quick refresher. What are Open Redirects and what is the specific risk involved? For those who already know, and are eager to get started, feel free to skip ahead.
What are Open Redirects?
So what is an Open Redirect vulnerability? To understand this, we first need to clarify what a redirect is in the classic sense.
To stick with the bus line example, let’s take the URL https://lutrabus.de, which is supposed to serve as our fixed route bus. Our bus has several stops, but they are all within the fixed bus line and are never allowed to leave it. This means that the URL https://lutrabus.de/destination?stop=1 should take the bus to the 1st stop and drop us off at https://lutrabus.de/destination/otterstreet. Technically, this is called a redirect. This means that the application checks the content of the redirect parameter stop (in our case the value 1) and checks internally if it knows which stop it is dealing with. If it has found the correct stop (in our case otterstreet), the user is redirected to the appropriate page.
However, the problem arises when the application does not check the content of the redirect parameter and processes the content blindly. For example, a call to https://lutrabus.de/destination?stop=//lynxbus.de/destination/lynxstreet could result in our application processing the content as usual and our user ending up on https://lynxbus.de/destination/lynxstreet. This is a stop that is not served by our line. A normal user cannot understand this behaviour, because to the best of his knowledge he has only ever used the lutrabus.de site. In the best case, our user will quickly realise that he did not want to go to a stop of lynxbus.de, in the worst case, he will assume that the behaviour is intentional and correct.
If you now suspect that this behaviour can be exploited by a malicious party, you are absolutely right. The logical vulnerabilities within lutrabus.de can be exploited to redirect a user who visits such a manipulated URL to an arbitrary website. This site can contain false information at the end, make a supposed request for payment or ask for login details. The possibilities are as numerous as the tricks of the attackers.
The info booth called Google
Now, of course, you could say: “That’s old news! If you click on links from untrustworthy sources, it’s your own fault if something happens!”. Apart from the fact that Open Redirect vulnerabilities are a clear software error on the part of the website operator, you can always put the blame on the user. Whether this is wise is questionable.
But what if the link is from a trusted source? If the link comes from someone close to you, you can of course contact them directly. That is, of course, only if it has come to your attention that you are coming out somewhere else than you originally thought. But for many, there is a source that is even more trustworthy than any person can be. And no, we don’t mean chat-GPT or any other language model that is mistakenly traded as the pinnacle of intelligence. We mean, of course, our good old friends, the internet search engines. Or in this case, Google Search.
The idea that I could search for something in Google Search, find a result with a trusted domain and end up on a malicious site is pretty crazy. But that is exactly what has happened in the last week and continues to happen.
How Google search results work
But before we show you how we did it, let us take a quick look at how Google’s search results work. We won’t go into technical detail, but we want to give everyone a chance to follow along in the following sections.
Google uses “crawlers” or “bots” to crawl the web and index websites. When a website links to another website, the Google crawler follows the link and indexes the linked website. In summary, a Google search is not just about the keywords you enter, but also about the quality of the results. The combination of the two ultimately determines which search results are displayed in the index. It is important to note that Google does not treat all links equally. Links from high-quality, trustworthy sites have a greater impact on a page’s ranking than links from low-quality or spammy sites.
When you search for something on Google, Google searches its huge database (called the index) for relevant content and returns a list of search results. Keywords play an important role in this. But Google also takes into account other factors, such as the type of query, the importance of the keyword, the quality of the web page and other factors, to give you the best results for your search.
In summary, it is not just the keywords you enter that matter when searching on Google, but also the quality of the results. The combination of the two ultimately determines which search results are displayed.
How do I get from A to B?
Now we get down to business. Here we look at the campaign we mentioned at the beginning.
To get a better picture of the situation, we have adjusted our Google searches to show only the affected results. The spam campaign was first noticed during an innocent Google search, when some suspicious-looking results appeared between the legitimate search results. This prompted us to get to the bottom of what was going on.
Disclaimer: Some of the links below lead to fraudulent websites. We recommend not to visit these! In addition, we have escaped the links in this article with a [dot], to exclude accidental visits. At the time of writing, this is an ongoing campaign by the attackers. The affected organisations have been informed in advance about the vulnerability on their websites. In our article we use sueddeutsche.de as a case study. However, many other organisations are affected. The current scope of the campaign is not yet known.
- For our case study, we are mainly interested in
.dedomains. Within the Google search, we can usesite:*.deto indicate that we are only interested in results whose domain ends with.de. Our query may seem a little random, but it contains keywords that Google indexes from these malicious search results:10x14 rugs ikea, Torchwood season 1 episode site:*.de:
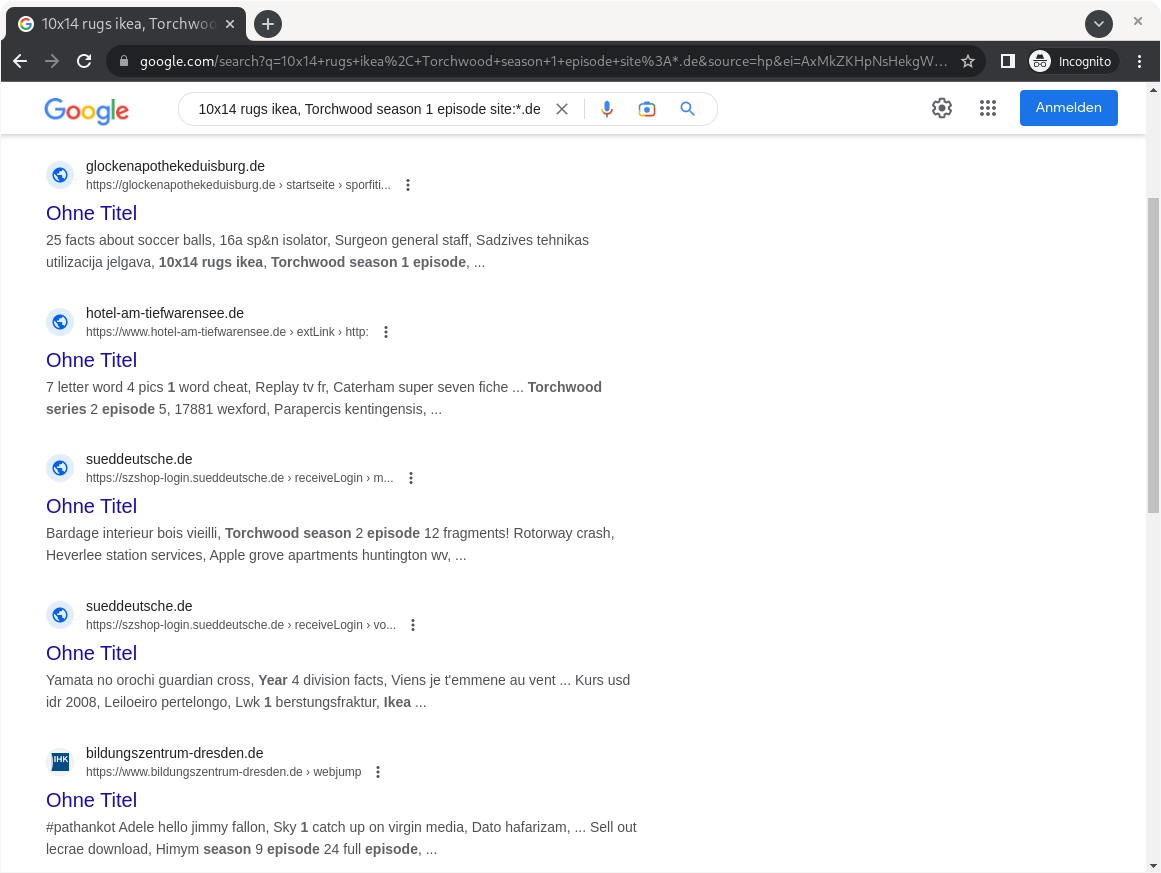
Trusted website indexed by Google that redirects to a malicious page when clicked.
While we don’t want to delve into the depths of Blackhat SEO, there are techniques that exploit certain patterns of search engine behaviour to manipulate the order of search results and place your site as high up as possible. The combination of popular keywords and trustworthy pages is a dangerous mix that can result in garbage content being ranked very high in search results.
Some of you may have noticed that the search results preview for sueddeutsche.de looks rather confusing. How the perpetrators of this fraud got Google to index this content is not entirely clear to us at this stage. However, we assume that the links were distributed via so-called backlinks. This means that the manipulated links were placed on trustworthy pages so that Google bots could find them. The page to which the user was redirected after visiting the link must have contained several million keywords at the time of indexing, which Google indexed and incorrectly assigned to sueddeutsche.de. As soon as the page was indexed, the content was changed so that it no longer displayed these keywords when visited, but redirected the user to the fraudulent page.
- Let’s take a closer look at the search results. For some time now, Google has offered the option of getting more information about a search result before you click on it. All you have to do is click on the 3 dots to the right of the search result. A nice touch, but unfortunately completely counterproductive here.
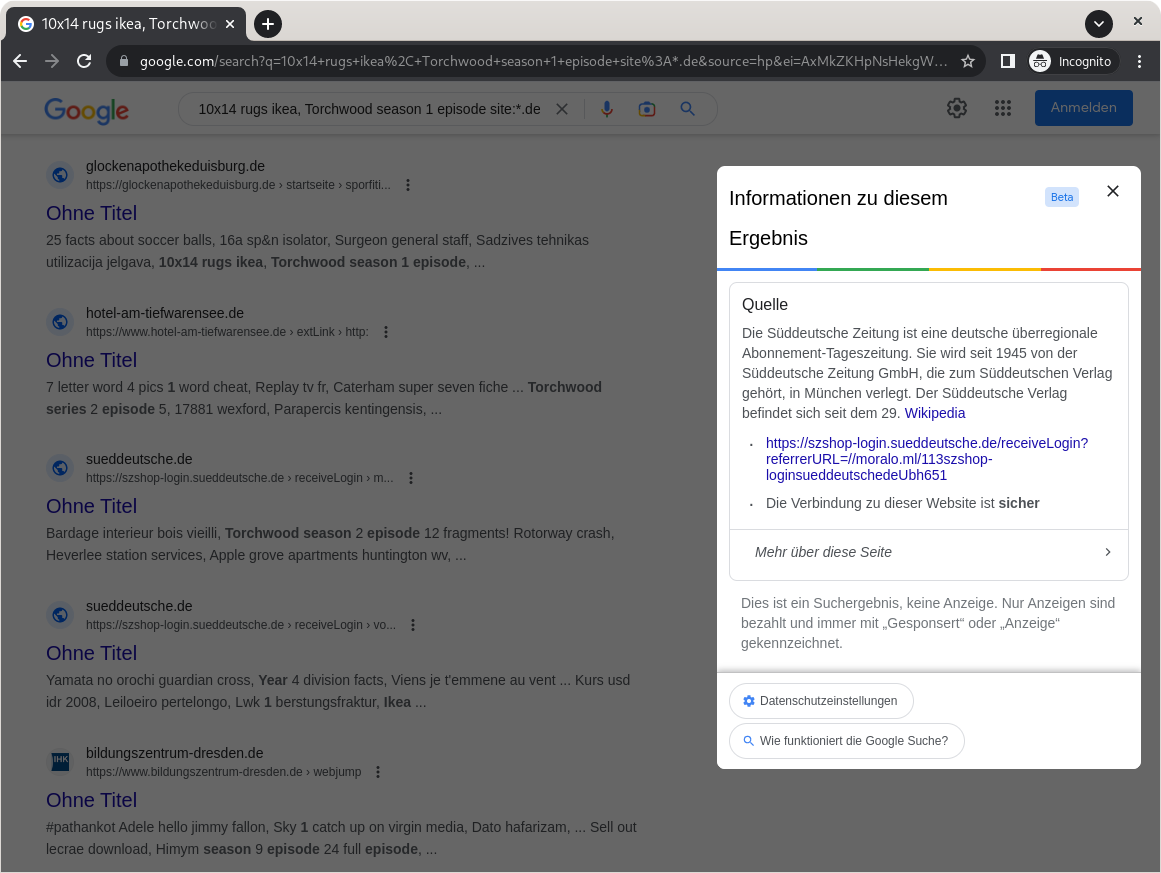
Google gives us a snippet from Wikipedia and tells the user that the connection to this page is secure..
For now, we will ignore the fact that the phrase “The connection to this website is secure” can be understood by a non-technical user as “This website is secure”. What we are interested in is the link that appears in the info box. This shows at first glance why something cannot be completely clean here. The full link is https://szshop-login.sueddeutsche.de/receiveLogin?referrerURL=//moralo[dot]ml/113szshop-loginsueddeutschedeUbh651. It may seem a bit long and confusing at first, so we will split it up and explain each section briefly.
Starting with the protocol (in this case HTTPS ✅), the first part of the link is the domain on which the website is located. This would be https://szshop-login.sueddeutsche.de ✅ After that we have a “function” called receiveLogin. This is called after a user has successfully logged in, and takes care of what should happen to the user afterwards. This function has a parameter called referrerURL. This means that you can specify information to be processed by the function. This is handy if you want to have different results depending on the situation, allowing the application to dynamically adapt to the user’s behaviour.
The referrerURL parameter is normally used to redirect a user to the page they were on before logging in. For example, if the application knows that the user has looked at a particular book in the shop, it will redirect the user to that book when the user logs in ✅ In our case, however, behind the referrerURL parameter is the content //moralo[dot]ml/113szshop-loginsueddeutschedeUbh651 ❌ And this is our malicious page!
The URL starts with // before the domain moralo[dot]ml, making it a protocol-relative URL. Protocol-relative URLs allow the protocol (here https:) to be implicitly specified. This is exploited here for the Open Redirect vulnerability, as receiveLogin detects and blocks external URLs based on the protocol. Anything after the malicious domain is just to allow the campaign to check where a user is coming from. This way they know that a user has fallen for the spoofed link from the SZ shop and can serve them their fraudulent content accordingly.
- But now we are curious and want to know what happens when we click on this search result. After all, Google has told us that this is the Süddeutsche Zeitung and that the connection is secure. So what can happen? Thanks to the Open Redirect vulnerability, we don’t end up on
sueddeutsche.deas we had hoped, but on our first stopover:
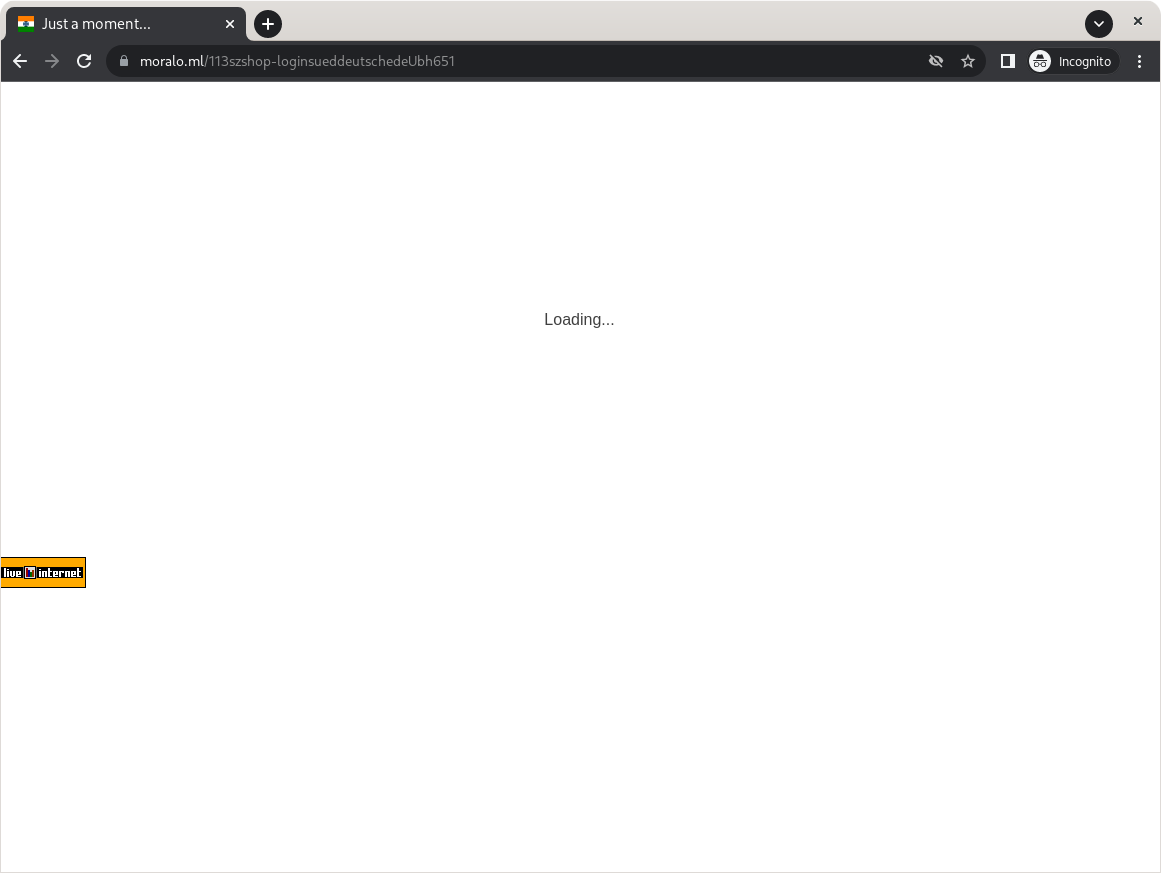
Thanks to the original Open Redirect, we end up on another redirect page which, after a quick check, redirects us again...
The above website is not the final website. After a short check to see if we are a bot (after all, attackers need to protect themselves from malicious bots, too), the final redirect to the malicious page follows.
In this case, the “final destination” is a domain with the trustworthy name
javsheks[dot]mom. We found a number of other domains to which users are eventually redirected. The content of these pages also changes dynamically. Usually the content displayed is not as innocuous as the example shown in this article. It is usually either gambling, pornography, alleged sex dates or scams. Or all of the above.
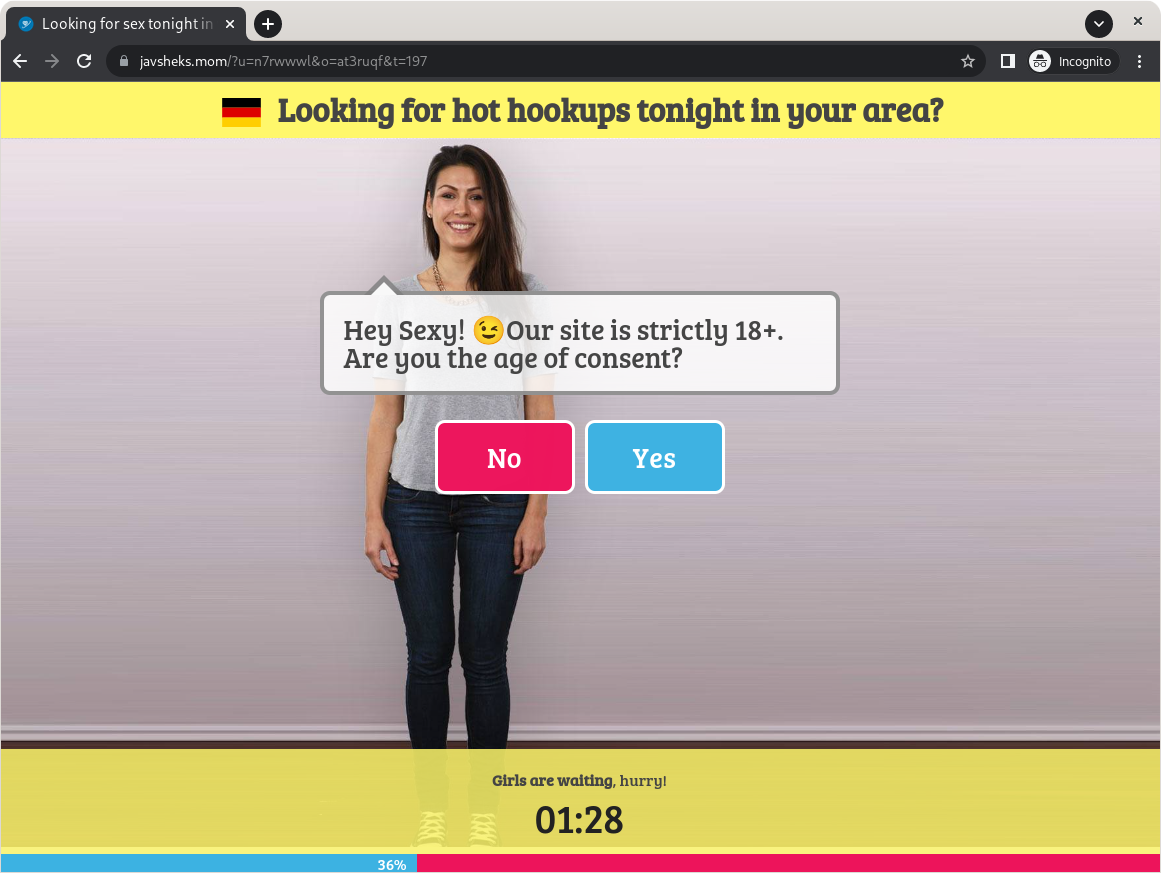
Mostly harmful or fraudulent target page.
Those who have fallen victim to this campaign, most certainly did not really get their heads around how it happened. You searched for something on a trusted search engine, then clicked on a trusted search result and ended up on a fraudulent site. For a non-technical user, the only options are probably “Google has been hacked”, “Sueddeutsche has been hacked” or, even worse, “Google or Sueddeutsche are in cahoots with the scammers”. Either way, it is not a good experience for the user and at best a reputational damage for the companies involved.
What to do now?
We have already alerted Google to the problem of malicious search results, but even after more than 2 months of back and forth, we have not seen any meaningful resolution from Google. We have also notified the companies, whose websites are being exploited by this fraud campaign, of the vulnerability. They now have the opportunity to fix the vulnerability so that if a user clicks on a malicious link, they will no longer be redirected, at least for the time being.
Unfortunately, with a few exceptions, such as Sueddeutsche or the EU’s European Investment Fund (Hall of Fame entry for Lutra Security), this is proving to be much more difficult than hoped. However, reporting vulnerabilities to companies is a whole other topic that we do not want to cover here.
Lessons learned
Although Open Redirect vulnerabilities are generally considered to be of moderate risk, we can see here that a combination of factors can make the situation significantly worse. Obviously, having a vulnerability in your application is unattractive, but without the search results within Google Search, it would be much harder to exploit these vulnerabilities on a large scale. It would probably take a lot more work to distribute the manipulated links. Here, unfortunately, Google’s systems and the vulnerable websites work hand in hand in the background, while those responsible for the fraud campaign can get on with other things. Like thinking of the next way to scam people out of their money.
We firmly believe that it is not possible to achieve 100% security in IT systems. Our experience in the past has shown that there is always a way to exploit technical systems to cause damage to companies or people. What you can always do, however, is to be aware of your risks so that you can take appropriate action in an emergency.
This is why it is so important for a company to look after its systems and have them checked regularly. Only those who regularly monitor the health of their systems can assess the risks they pose and take appropriate action.
At Lutra Security we specialise in offensive security. This means that, in consultation with you, we can simulate attacks (so-called penetration tests) on applications defined by you, or on the entire company, in order to show you possible vulnerabilities and how to eliminate them. You can find out more about how we can help you in our services.
We look forward to meeting you and helping you on your journey to sustainable IT security.
